Задача соединения
Задача соединения состоит в нахождении среднего значения pageRank набора страниц, посещенных из sourceIP, которые принесли наибольший доход от рекламы в течение недели с 15 по 22 января 2009 г. Ключевое различие между этой и предыдущими задачами состоит в том, что теперь требуется считывать данные из двух разных наборов данных и соединять эти данные (информация о рейтинге станиц (pageRank) находится в таблице Rankings, а информация о доходе от рекламы (adRevenue) – в таблице UserVisits). В таблице UserVisits имеется примерно 134000 записей, у которых значение атрибута visitDate попадает в заданный интервал времени.
В отличие от трех предыдущих задач, мы не могли использовать одни и те же формулировки запросов на SQL и для параллельных систем баз данных, и для систем, основанных на Hadoop. Это связано с тем, что версия Hive, которую мы расширяли, требуемый запрос обработать не могла. Хотя эта версия принимала на обработку SQL-запрос, который соединял, отфильтровывал и агрегировал кортежи из двух таблиц, выполнить сгенерированный план в среде Hadoop не удавалось. Кроме того, мы заметили, что в плане запросов с соединениями данного типа использовалась исключительно неэффективная стратегия выполнения. В частности, операция фильтрации планировалась позже соединения таблиц. Поэтому для такого запроса мы можем представить только результаты выполнения планов, закодированых вручную.
В HadoopDB мы проталкивали в экземпляры SQL фильтрацию, соединение и частичную агрегацию с использованием следующего SQL-запроса:
SELECT sourceIP, COUNT(pageRank), SUM(pageRank), SUM(adRevenue) FROM Rankings AS R, UserVisits AS UV WHERE R.pageURL = UV.destURL AND UV.visitDate BETWEEN ‘2000-01-15’ AND ‘2000-01-22’ GROUP BY UV.sourceIP;
Затем мы использовали в Hadoop одну задачу Reduce, которая собирала все частичные агрегаты от всех экземпляров PostgreSQL и выполняла окончательную агрегацию.
Параллельные системы баз данных выполняли тот же SQL-запрос, что и в .
Хотя в Hadoop имеется поддержка операции соединения, для ее выполнения требуется, чтобы оба набора данных были отсортированы по ключу соединения. Это требование ограничивает применимость операции соединения, поскольку во многих случаях, включая рассматриваемый запрос, такая сортировка автоматически не обеспечивается, а выполнение сортировки до соединения добавляет существенные накладные расходы. Мы установили, что даже если бы мы отсортировали входные данные (и не включили бы время сортировки в общее время выполнения запроса), производительность запроса на основе Hadoop-соединения была бы ниже производительности запроса с использованием трехфазной MR-программы, применявшейся в (которая основывалась на стандартных операциях 'Map' и 'Reduce'). Поэтому наши результаты получены путем использования той же MR-программы, которая использовалась (и подробно описывалась) в .
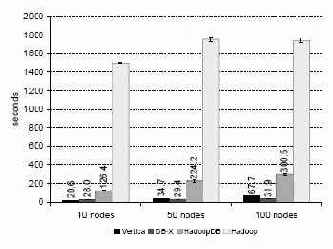
Рис. 9. Задача соединения
На рис. 9 приводится сводка результатов, полученных при прогонах этой тестовой задачи. Для Hadoop получены результаты, аналогичные приведенным в : производительность системы ограничивается тем, что она полностью сканирует набор данных UserVisits в каждом узле для выполнения фильтрации данных.
HadoopDB, СУБД-X и Vertica показывают более высокую производительность за счет использования индексов для ускорения фильтрации и наличия естественной поддержки соединений. Эти системы демонстрируют незначительное ухудшение производительности при увеличении числа узлов из-за финальной одноузловой агрегации adRevenue и сортировки по полученным агрегатным значениям.
