
Задача агрегации
В следующей задаче вычисляются суммы значений атрибута adRevenue (доходы от рекламы) для групп кортежей таблицы UserVisits, получаемых путем группировки этой таблицы либо по первым семи символам столбца sourceIP, либо по всему этому столбцу. В отличие от предыдущих задач, при решении этой задачи требуется обмен промежуточными результатами между разными узлами кластера (чтобы можно было вычислить окончательные агрегатные значения). При группировке по семибайтному префиксу образуется 2000 уникальных групп. При группировке по всему sourceIP число таких групп составляет 2500000.
В системах Vertica, СУБД-X, HadoopDB и Hadoop (Hive) выполнялись одни и те же SQL-запросы:
небольшой запрос:
SELECT SUBSTR(sourceIP, 1, 7), SUM(adRevenue) FROM UserVisits GROUP BY SUBSTR(sourceIP, 1, 7);
крупный запрос:
SELECT sourceIP, SUM(adRevenue) FROM UserVisits GROUP BY sourceIP;
В Hadoop (с кодированием вручную) это задание выполнялось в точности так же, как в : функция Map выводит adRevenue и первые семь символов поля sourceIP (или все поле в случае крупного запроса), и эти данные передаются функции Reduce, которая выполняет требуемую агрегацию для каждого префикса (или всего значения) sourceIP.
В HadoopDB планировщик SMS проталкивает весь SQL-запрос в экземпляры PostgreSQL. Полученные результаты передаются задачам Reduce в Hadoop, которые выполняют окончательную агрегацию (после сбора всех предварительных частичных агрегатов от всех экземпляров).
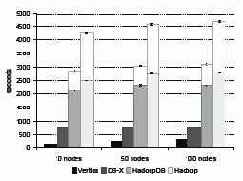
Рис. 7. Крупная задача агрегации

Рис. 8. Малая задача агрегации
Показатели производительности всех сравниваемых систем показаны на рис. 7 и 8. Аналогично задаче Grep, на время выполнения этого запроса влияет скорость чтения с диска. Поэтому обе коммерческие системы получают преимущества от сжатия данных и превосходят по производительности HadoopDB и Hadoop.
"Малая" (с группировкой по подстроке) задача агрегации демонстрирует исключение из того общего правила, что Hive добавляет накладные расходы к Hadoop, кодируемому вручную (на рис. 8 время, затраченное Hadoop при выполнении плана, который был подготовлен с использованием Hive, представлено нижней частью столбца Hadoop). План, подготовленный Hive, выполняется гораздо быстрее задания, закодированного вручную, потому что в нем используется стратегия хэш-агрегации (на фазе Map задания поддерживается внутренняя схема хэширования-агрегации), которая оказывается оптимальной при небольшом числе групп. При решении крупной задачи агрегации Hive переключается на стратегию агрегации путем сортировки, обнаруживая, что число групп превышает половину числа входных записей, помещающихся в одном блоке. В плане для Hadoop, закодированном нами (и авторами ) вручную, мы не смогли применить хэш-агрегацию для "малого" запроса, потому что общепринятой практикой MapReduce является использование агрегации путем сортировки (с применением комбинаторов (combiner)).
Эти результаты иллюстрируют преимущество использования оптимизаторов, которые присутствуют в системах баз данных и системах обработки реляционных запросов, подобных Hive, и могут использовать статистические данные из каталогов системы или простые правила оптимизации для выбора между хэш-агрегацией и агрегацией путем сортировки.
В отличие от комбинаторов Hadoop, Hive сериализует частичные агрегаты в строки, а не поддерживает их в естественном бинарном представлении. Поэтому при обработке крупного запроса план, построенный Hive, выполняется намного дольше плана, закодированного для Hadoop вручную.
В PostgreSQL при решении обеих задач используется хэш-агрегация, поскольку таблица хэш-агрегации для каждого гигабайтного чанка легко помещается в основной памяти. Из-за применения этой эффективной реализации агрегации HadoopDB превосходит по производительности Hadoop при решении обеих задач.
Эти запросы хорошо подходят для систем с поколоночным хранением таблиц, поскольку два атрибута, требуемые для выполнения запроса (sourceIP и adRevenue) включают всего 20 байт из более чем 200 байт каждой записи UserVisits. Из-за соответствующей экономии ввода-вывода производительность Vertica оказывается значительно выше производительности других систем.