
Тестовые испытания для сравнения производительности и масштабируемости
В первой тестовой задаче ("задаче Grep") требуется просканировать набор данных, состоящий из 100-байтных записей, для нахождения записей, которые содержат заданный шаблон из трех символов. Это единственная задача, в которой требуется обработка большей частью неструктурированных данных, и она была включена в тестовый набор авторами , поскольку упоминалась в исходной статье про MapReduce .
Для изучения более сложных случаев использования сравниваемых систем в тестовый набор были включены четыре в большей степени аналитические задачи, связанные с анализом журнальных файлов и HTML-документов. Три задачи работают над структурированными данными, а последняя – как над структированными, так и над неструктурированными данными.
Набор данных, с которым работают эти четыре задачи, включает таблицу UserVisits, моделирующую журнальные файлы трафика HTTP-сервера, таблицу Documents, содержащую 600000 случайным образом сгенерированных HTML-документов, и таблицу Ranking, которая содержит некоторые метаданые, вычисленные на основе данных из таблицы Documents. Схемы таблиц тестового набора подробно описаны в . Вкратце, таблица UserVisits содержит 9 атрибутов, наиболее крупным из которых является destinationURL, имеющий тип VARCHAR(100. Каждый кортеж включает примерно 150 байт. Таблица Documents содержит два атрибута: URL (VARCHAR(100)) и contents (произвольный текст). Наконец, таблица Ranking содержит три атрибута: pageURL (VARCHAR(100)), pageRank (INT) и avgDuration (INT).
Генератор данных производит по 155 миллионов записей UserVisits (20 гигабайт) и 18 миллионов записей Ranking (1 гигабайт) на каждый узел. Поскольку генератор данных не обеспечивает попадание в один узел кортежей Ranking и UserVisits с одним и тем же значением атрибута URL, во время загрузки данных производится их переразделение, как описывается ниже.
Записи наборов данных UserVisits и Ranking сохраняются в HDFS в виде плоского текста, по одной записи в строке с полями, разделяемыми специальным символом-разделителем. Для обеспечения доступа во время выполнения к разным атрибутам функции Map и Reduce расщепляют запись по разделителю, образуя массив строк.
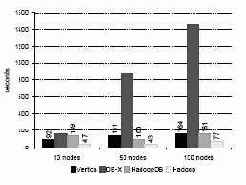
Рис. 3. Загрузка данных для задачи Grep (0,5 гигабайта на узел)
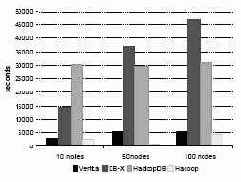
Рис. 4. Загрузка набора данных UserVisits (20 гигабайт на узел)